


The Best NEW Use Cases Of GPT-4V (GPT Can See👀)
In this article, we will go over the mind boggling technology that is GPT-4V, and some of its newest an most unique use cases!

The Dawn of Multimodal AI
The world of artificial intelligence has been buzzing with the advent of large language models (LLMs) like GPT-4, which have shown remarkable versatility across various domains. But what if we could push the envelope even further? Enter GPT-4 with Vision (GPT-4V), the next evolutionary leap in AI that's not just about understanding text but also about interpreting images. Imagine an AI that can not only write an essay for you but also analyze a painting or even a medical X-ray. That's the kind of game-changing capability we're talking about here.
GPT-4V enables users to instruct the model to analyze image inputs, making it a multimodal large language model (LMM). This is seen as a key frontier in AI research and development. The idea is to expand the impact of language-only systems by adding novel interfaces and capabilities, such as image inputs. This allows these advanced models to solve new tasks and offer novel experiences to users. Safety is also a significant focus, with OpenAI diving deep into evaluations, preparation, and mitigation work specifically for image inputs.
-OpenAI
But why focus on vision? As Microsoft's paper "The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)" points out, vision is dominant in human senses. The paper explores the emergent multimodal abilities of LMMs like GPT-4V, which are developed based on state-of-the-art LLMs. The research investigates the use of a vision encoder aligned with a pre-trained LLM or a vision-language model to convert visual inputs into text descriptions. The paper is a must-read for anyone looking to delve deeper into this fascinating topic of vision in AI.
So, what does all this mean for us? It means we're on the cusp of an AI revolution where our interactions with technology could become more intuitive and human-like. Imagine asking your AI assistant to not just find a recipe but also to analyze the nutritional content of a dish based on a photo. Or think about healthcare applications where an AI could assist in diagnosing conditions through medical imaging. The possibilities are endless, and we're just scratching the surface.
For those interested in a deeper dive into the vision capabilities of large multimodal models, the paper by Microsoft "The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)" is an excellent resource.👇
History of Vision in AI
The development of vision models in AI has been a remarkable journey, punctuated by breakthroughs and paradigm shifts that have continually shaped our understanding of machine perception. In the late '90s and early 2000s, simple edge detection and blob analysis were the rage, laying foundational bricks but showing clear limitations.

Fast-forward to 2012, the watershed year when AlexNet took the world by storm, beating the competition by a huge margin in the ImageNet Large Scale Visual Recognition Challenge. This success invigorated interest in deep learning, eventually leading to more complex architectures like VGG, ResNet, and Inception. These models unlocked incredible capabilities but were still largely siloed from other AI domains like natural language processing. Then came the multimodal models, integrating vision with language, resulting in game-changers like CLIP. And now, we find ourselves at the frontier with GPT-4V, a leap that could represent a symbiotic marriage between visual understanding and language proficiency. This isn't just an incremental step; it's similar to the moon landing for AI vision.
How do you (even) use this?
Well, it’s quite simple actually. GPT-4V is currently available to all plus users on chat.openai.com, making the subscription all the more valuable or AI enthusiasts. Once you’ve paid for plus, you should see GPT-4 as a model on the top of your screen.

Hover over “GPT-4”, and click the default option. Once you’ve done this, you should see a small image icon in the bottom left of the chatbox. This is what you click to input images into chatgpt. And it’s that simple!
10+ of The Newest Use Cases
🔗https://x.com/petergyang/status/1708237323945889798?s=20
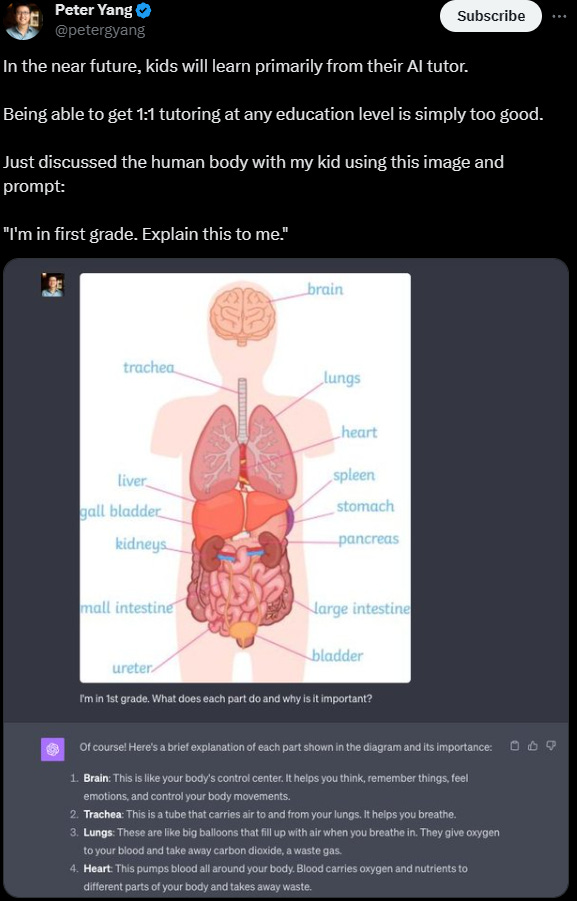
🔗https://x.com/mckaywrigley/status/1707408491110080602?s=20

🔗https://x.com/petergyang/status/1707119323729580416?s=20

🔗https://x.com/mckaywrigley/status/1708557028149673990?s=20





🔗https://x.com/skirano/status/1707466657176637709?s=20

Uses Cases from Microsoft’s Paper (Insane!)
(Click the photos to open the paper)
Celebrity Recognition and Description

Landmark Recognition and Description

Food Recognition and description

Medical Image Understanding

Spatial Relationship Understanding

Understanding Memes
